第一次学习 MLSys, 谨做记录和总结.
Tensor Parallelism
考虑一个矩阵乘法: , 其中 是 weight, 是输入.
第一种是行分割:
最后要在所有卡上做一个 all_reduce 的操作对结果做汇总.
第二种是列分割:
最后要在所有卡上做一个 all_gather.
在训练阶段, 无论是何种方式切分, 都会在 forward 和 backward 各产生一次额外通信. 如果有连续的矩阵乘法, 通过先列分割再行分割可以把一对 all_gather/split 抵消.
model weight loader 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| > nanovllm/engine/model_runner.py:l 32 --> ModelRunner.__init__
load_model(self.model, config.model)
> nanovllm/utils/loader.py:def load_model
def load_model(model: nn.Module, path: str):
packed_modules_mapping = getattr(model, "packed_modules_mapping", {})
for file in glob(os.path.join(path, "*.safetensors")):
with safe_open(file, "pt", "cpu") as f:
for weight_name in f.keys():
for k in packed_modules_mapping:
if k in weight_name:
v, shard_id = packed_modules_mapping[k]
param_name = weight_name.replace(k, v)
param = model.get_parameter(param_name)
weight_loader = getattr(param, "weight_loader")
weight_loader(param, f.get_tensor(weight_name), shard_id)
break
else:
param = model.get_parameter(weight_name)
weight_loader = getattr(param, "weight_loader", default_weight_loader)
weight_loader(param, f.get_tensor(weight_name))
> nanovllm/models/qwen3.py:l 185 --> Qwen3ForCausalLM
packed_modules_mapping = {
"q_proj": ("qkv_proj", "q"),
"k_proj": ("qkv_proj", "k"),
"v_proj": ("qkv_proj", "v"),
"gate_proj": ("gate_up_proj", 0),
"up_proj": ("gate_up_proj", 1),
}
> nanovllm/models/qwen3.py:l 41 --> Qwen3Attention.__init__
self.qkv_proj = QKVParallelLinear(
hidden_size,
self.head_dim,
self.total_num_heads,
self.total_num_kv_heads,
bias=qkv_bias,
)
> nanovllm/models/qwen3.py:l 97 --> Qwen3MLP.__init__
self.gate_up_proj = MergedColumnParallelLinear(
hidden_size,
[intermediate_size] * 2,
bias=False,
)
> nanovllm/layers/linear.py:def QKVParallelLinear.weight_loader
def weight_loader(self, param: nn.Parameter, loaded_weight: torch.Tensor, loaded_shard_id: str):
param_data = param.data
assert loaded_shard_id in ["q", "k", "v"]
if loaded_shard_id == "q":
shard_size = self.num_heads * self.head_size
shard_offset = 0
elif loaded_shard_id == "k":
shard_size = self.num_kv_heads * self.head_size
shard_offset = self.num_heads * self.head_size
else:
shard_size = self.num_kv_heads * self.head_size
shard_offset = self.num_heads * self.head_size + self.num_kv_heads * self.head_size
param_data = param_data.narrow(self.tp_dim, shard_offset, shard_size)
loaded_weight = loaded_weight.chunk(self.tp_size, self.tp_dim)[self.tp_rank]
param_data.copy_(loaded_weight)
> nanovllm/layers/linear.py:l 23 --> LinearBase.__init__
self.tp_dim = tp_dim
self.tp_rank = dist.get_rank()
self.tp_size = dist.get_world_size()
|
forward 的实现:
Embedding:
1
2
3
4
5
6
7
8
9
10
| > nanovllm/layers/embed_head.py:l 35 --> VocabParallelEmbedding.forward
def forward(self, x: torch.Tensor):
if self.tp_size > 1:
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx)
x = mask * (x - self.vocab_start_idx)
y = F.embedding(x, self.weight)
if self.tp_size > 1:
y = mask.unsqueeze(1) * y
dist.all_reduce(y)
return y
|
用 y = mask.unsqueeze(1) * y 把不属于本卡的归零,用 dist.all_reduce(y) 汇总.
在 Attention 之前, 每个卡都有完整的 embedding. 每个 Attention 都采用 Pre-Norm 归一化. 每个 Attention 在 num_heads 维度上做列切分, 进一步提高并行化程度. 叠加 QKNorm, 每一层都添加 RoPE. 最后的 attn_o MLP 是单层线性层, 采用行切分和 dist.all_reduce().
1
2
3
4
5
6
7
8
9
10
| > nanovllm/layers/linear.py:l 120 --> QKVParallelLinear.__init__
self.num_heads = divide(self.total_num_heads, tp_size)
self.num_kv_heads = divide(self.total_num_kv_heads, tp_size)
> nanovllm/layers/linear.py:def RowParallelLinear.forward
def forward(self, x: torch.Tensor) -> torch.Tensor:
y = F.linear(x, self.weight, self.bias if self.tp_rank == 0 else None)
if self.tp_size > 1:
dist.all_reduce(y)
return y
|
Attention 后的 MLP 是两层线性层, 激活函数是 SiLU, 元素之间独立, 线性层采用先列切分再行切分的方法减少一次通信.
模型的初始化与标准化
用二阶矩来衡量输出的稳定性, 对于一个单层的无激活函数的全连接线性网络层来说 (假设输入 channel 数为 , 输出 channel 数为 ), 简单起见, 我们用零初始化 bias, 并且将 的均值也设为 . 我们计算二阶矩:
所以为了使 为 , 那么 , 这就是 LeCun 初始化.
如果考虑激活函数, 比如采用 relu, 那么可以假设有大概一半的输出 被归零了, 从而初始化的方差为 , 这就是专门针对 relu 网络的 He 初始化.
对于其他的激活函数, 有可能无论如何修改初始化都无法控制二阶矩, 这时需要"微调"激活函数.
以 sigmoid 为例, 假设我们依然以均值为 , 方差为 来初始化, 那么激活前的输出也是均值为 , 方差为 , 用标准正态分布估计 sigmoid 后的二阶矩:
1
2
3
| NIntegrate[1/Sqrt[2*Pi]*Exp[-x^2/2]*1/(1+Exp[-x])^2, {x, -Infinity, Infinity}]
0.293379
|
所以, 如果我们希望保持输出的二阶矩不变, 那么可以把输出结果除以 .
2017 这篇论文 Self-Normalizing Neural Networks 提出了 SELU 激活函数, 其定义为
其中 . 论文中给出的 的值可以使得标准正态分布经过 SELU 激活函数后, 均值和方差都不变. 只能算得上一种好的初始化方法.
1
2
3
4
5
6
7
| F[x_] = Exp[-x^2/2]/Sqrt[2*Pi];
Selu[x_] = Piecewise[{{\[Lambda]*x, x > 0}, {\[Lambda]*\[Alpha]*(Exp[x] - 1), x <= 0}}];
x1 = Integrate[F[x]*Selu[x], {x, -Infinity, Infinity}];
x2 = Integrate[F[x]*Selu[x]^2, {x, -Infinity, Infinity}];
N[Solve[{x1 == 0, x2 == 1}, {\[Lambda], \[Alpha]}], 20]
{{\[Lambda] -> -1.0507009873554804934, \[Alpha] -> 1.6732632423543772848}}
|
当然相比于这种"微调", 更直接的是各种 Normalization 方法, 通过直接计算当前数据的均值和方差来归一化, 而非预先估计积分. 虽然 Normalization 都包含 centering 和 scaling 两个步骤, 但越来越多的工作逐渐尝试去掉 centering 这一步, 甚至有些工作表明去掉 centering 反而能提升模型的性能.
比如 Root Mean Square Layer Normalization 提出的 RMSNorm, 就表明相比 LayerNorm 更快且保持基本一致的效果.
类似地, 同样是 2019 年的文章, Analyzing and Improving the Image Quality of StyleGAN 发现使用了 InstanceNorm 后图片会带有"水滴", 而保留 InstanceNorm 单去掉 centering 能改善这个现象, 这也为 centering 有可能带来负面影响提供了佐证.
关于残差连接 , 假设 与 两者独立, 那么 的方差为 , 会进一步放大方差, 一种朴素的方法是直接在残差相加之后加入 Normalization 操作:
这种 Post Norm 的结构, 是原版 Transformer 和 BERT 所采用的, 这种虽然稳定了正向传播的方差, 但是会削弱残差连接中的恒定项, 所以反而失去了残差易于训练的优点, 通常要 Warmup 并设置足够小的学习率才能收敛.
一个针对性的改进是 Pre Norm, 其形式为:
迭代展开后有:
至少每一个残差项都是平权的, 作用会相比 Post Norm 更大, 所以也更容易优化. 当然, 这样的输出方差会很大, 在预测层之前需要加一个 Normalization.
为什么 Pre Norm 的效果会不如 Post Norm? 回顾我们的迭代展开式, 每一项都是同一量级的, 因为有 , 当深度很深的时候, 与 的相对差别是比较小的, 因此:
因此原本一个 层模型的输出和 输出的结果相加, 近似于一个更宽的 层模型, 所以在 Pre Norm 中多层叠加的结果在更深的模型中是增加宽度而非增加深度, 层数越多, 层数越"虚".
Prepare
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| > nanovllm/engine/scheduler.py:l 34 --> Scheduler.schedule
self.block_manager.allocate(seq)
> nanovllm/engine/block_manager.py:def BlockManager.allocate
def allocate(self, seq: Sequence):
assert not seq.block_table
h = -1
cache_miss = False
for i in range(seq.num_blocks):
token_ids = seq.block(i)
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1
block_id = self.hash_to_block_id.get(h, -1)
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss:
block_id = self.free_block_ids[0]
block = self._allocate_block(block_id)
else:
seq.num_cached_tokens += self.block_size
if block_id in self.used_block_ids:
block = self.blocks[block_id]
block.ref_count += 1
else:
block = self._allocate_block(block_id)
if h != -1:
block.update(h, token_ids)
self.hash_to_block_id[h] = block_id
seq.block_table.append(block_id)
|
在这里实现了 prefix caching, 每一次处理请求, 都会逐块计算哈希, 判断是否在缓存块中. 计算哈希的时候会把 prefix 的哈希也考虑进去, 不会发生 AAA 和 AAABBBAAA 的后面的 AAA 复用缓存的问题.
1
2
| > nanovllm/engine/model_runner.py:l 209 --> ModelRunner.run
input_ids, positions = self.prepare_prefill(seqs) if is_prefill else self.prepare_decode(seqs)
|
如果是 prefill, model 需要做 varlen 的 attention, 首先将所有未处理的 input_ids 拼接在一起, 作为输入 q 的总长度, 每一个序列的总长度相加是 kv 的长度, positions 是相对每一个序列的开始到结束的区间, 用来构建 mask 矩阵. slot_mapping 记录了每一个新进入的 q 对应的 kv cache 在 pool 里的位置, 通过 block_id * block_size 得到开始位置. block_table 记录了每一个 seq 对应的 kv cache block_id(s).
如果是 decode, 则只需要添加最后的 input_id, 总体相似.
KV Cache 管理
接下来我们看如何对 kv cache 进行管理.
在初始化 ModelRunner 的时候, 加载完模型后会用最大的 batch workload 来 warmup, 根据峰值的占用计算剩余空间, 得到块数量.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| > nanovllm/engine/model_runner.py:def ModelRunner.allocate_kv_cache
def allocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
num_kv_heads = hf_config.num_key_value_heads // self.world_size
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * hf_config.head_dim * hf_config.torch_dtype.itemsize
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes
assert config.num_kvcache_blocks > 0
self.kv_cache = torch.zeros(2, hf_config.num_hidden_layers, config.num_kvcache_blocks, self.block_size, num_kv_heads, hf_config.head_dim)
layer_id = 0
for module in self.model.modules():
if hasattr(module, "k_cache") and hasattr(module, "v_cache"):
module.k_cache = self.kv_cache[0, layer_id]
module.v_cache = self.kv_cache[1, layer_id]
layer_id += 1
|
根据计算的结果开合适的块数量, 并同步到 Scheduler 的 config 中, 随后把每一层的块都放在 Attention 模块中. 值得注意的是, 这些操作是随着 ModelRunner 的初始化做的, 所以是每个节点独立的, 因此开的块大小也是根据 TP 分好的.
在计算 attention 之前, 会根据 slot_mapping 把输入的 kv 写入缓存块中. 并将整个 kv_cache 丢进 FLA, 根据 block_table 来寻址.
关于 Scheduler
prefill 会让 kv_cache_block_manager try_allocate 而 decode 会让 kv_cache_block_manager try_append.
如果 try_append 失败, 则会把已经保存的 kv_cache_block deallocate.
Graph 模式
为什么 prefill 不用 Graph 模式加速, 而 decode 阶段使用? CUDA Graph 是用来优化和加速启动 kernel 的开销, 而 prefill 是 compute-bound 的, kernel 启动的成本并不是瓶颈, 且输入长度不固定, 很难复用图.
首先, 捕获图, 输入的 batch_size 是固定大小, block_table 开最大.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| > nanovllm/engine/model_runner.py:l 228 --> ModelRunner.capture_cudagraph
self.graph_bs = [1, 2, 4, 8] + list(range(16, max_bs + 1, 16))
self.graphs = {}
self.graph_pool = None
for bs in reversed(self.graph_bs):
graph = torch.cuda.CUDAGraph()
set_context(False, slot_mapping=slot_mapping[:bs], context_lens=context_lens[:bs], block_tables=block_tables[:bs])
outputs[:bs] = self.model(input_ids[:bs], positions[:bs])
with torch.cuda.graph(graph, self.graph_pool):
outputs[:bs] = self.model(input_ids[:bs], positions[:bs])
if self.graph_pool is None:
self.graph_pool = graph.pool()
self.graphs[bs] = graph
torch.cuda.synchronize()
reset_context()
self.graph_vars = dict(
input_ids=input_ids,
positions=positions,
slot_mapping=slot_mapping,
context_lens=context_lens,
block_tables=block_tables,
outputs=outputs,
)
|
在 decode 阶段, batch_size 会向上取整, 然后按需填充 batch_size 和 block_table.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| > nanovllm/engine/model_runner.py:l 193 --> ModelRunner.run_model
bs = input_ids.size(0)
context = get_context()
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)]
graph_vars = self.graph_vars
for k, v in graph_vars.items():
if k != "outputs":
v.zero_()
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
graph.replay()
return self.model.compute_logits(graph_vars["outputs"][:bs])
|
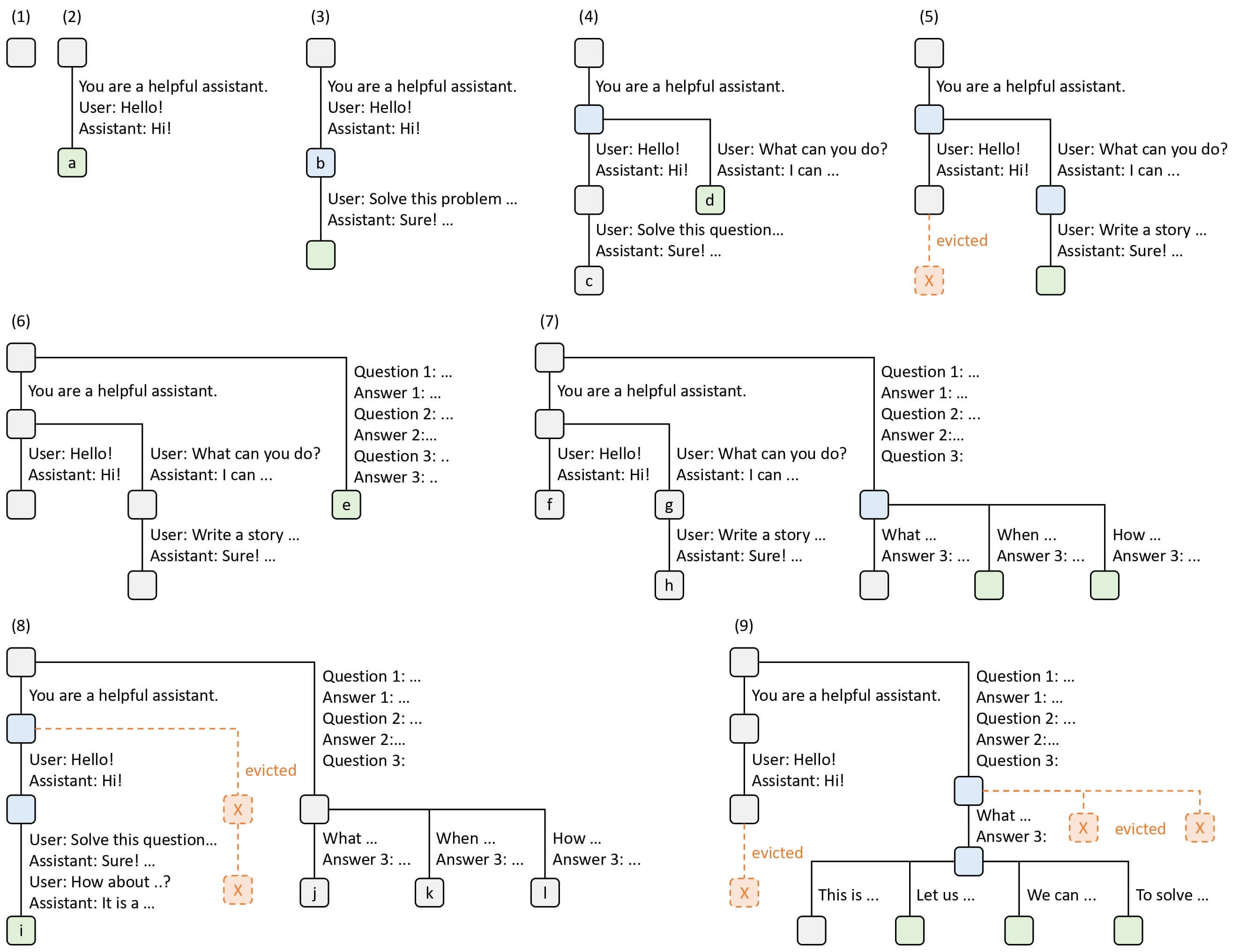
Prefix Caching
前面提到了 nano-vllm 实现了基于 PageAttention 的 prefix caching, 下面简单学习一下.
Prefix Caching 主要减少 Latency, 在以下场景中有明显的作用: Few-shot Learning, Self-consistency, Multi-turn Chat, Tree-of-Thought.
主要的算法是 Radix Attention, 通过前缀哈希共享建树, 并用 LRU 逐块.
![image]()
通过前缀哈希, 构造前缀树, 很巧妙地保持了一致性.