
Link: Angles Don't Lie: Unlocking Training-Efficient RL Through the Model's Own Signals.
是和我关系非常好的博一学长的工作, 借着机会学习一下如何做研究, 认真读了一下, 觉着思路非常好, 写一下感受. 笔者也不懂 RL 和 Post Training, 很多地方只能靠感受来理解.
文章针对 Post Training 中训练样本效率问题, 例如, 使用 GRPO 微调 7B 模型需要消耗 240 卡时 (16卡
- 设计数据时没有考虑模型的反应. 无论是数据的难度和多样性, 都是假定模型不可知的, 但是不同的模型对于同样的数据反应不同, 所以这类不考虑模型的方法并不能达到最好的效果.
- 数据准备成本高. 无论是精选数据亦或是依据难度分层, 都需要模型对问题的正确率或者人类标注.
Which signal should we focus on?
如果想要在 decoding 阶段得到模型的 feedback 是消耗很多计算的, 约等于直接依赖正确率, 相反, pre-filling 阶段的计算更少, 需要一次正向输入. 下面我们来理解正向过程是如何影响反向传播的.
对于一个权重矩阵
下面考虑梯度的范数, 这里用 Frobenius 范数,
又因为
因为一般情况下, 输入都是经过归一化的, 这里经过变化的
在包含激活函数和 Attention Mechanism 的网络结构中, 类似的结果也成立, 具体证明结果在附录中.
Which signal should we focus on?
文章发现, 相对角度在网络中呈凝聚现象, 层数越深, 越呈现分块凝聚. 并且分块的部位准确的分割了输入: system prompt, few-shot examples, question 三个部分.
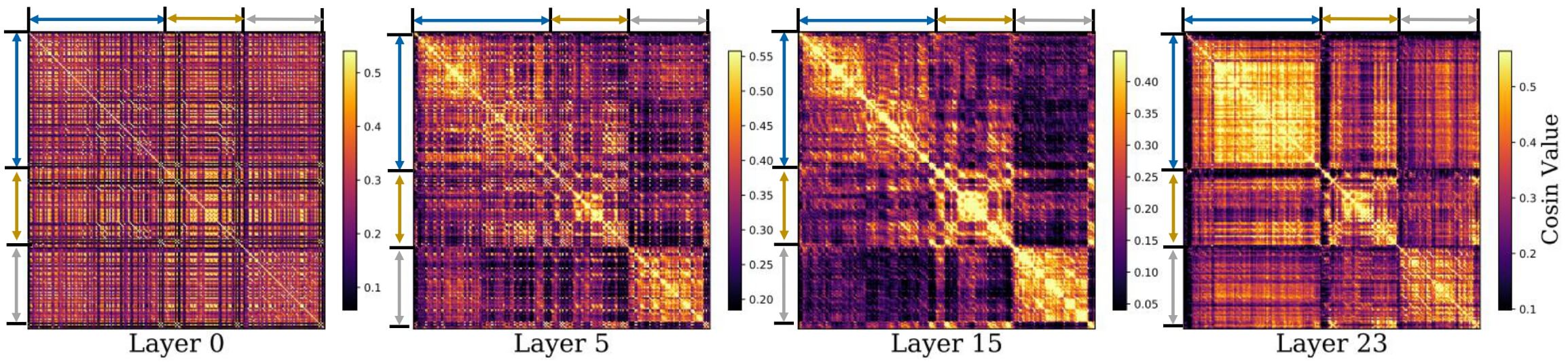
假设输入总长度为
How Can This Signal Be Leveraged to Accelerate Training?
然后, 文章发现, 在训练过程中, 上述两个信号都在稳定增加, 且信号越强的样本, 学习的越快.
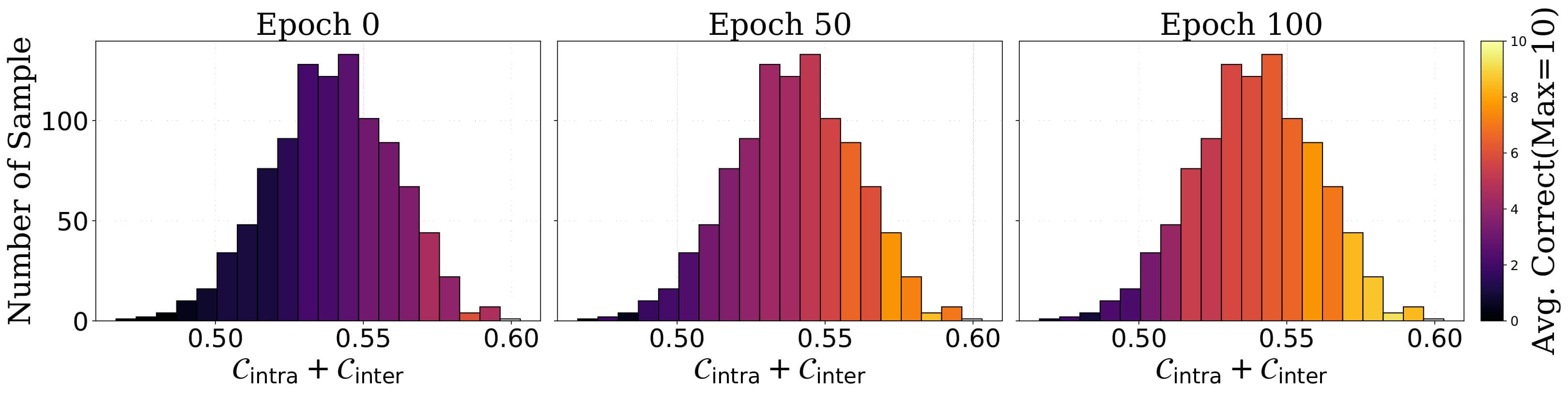
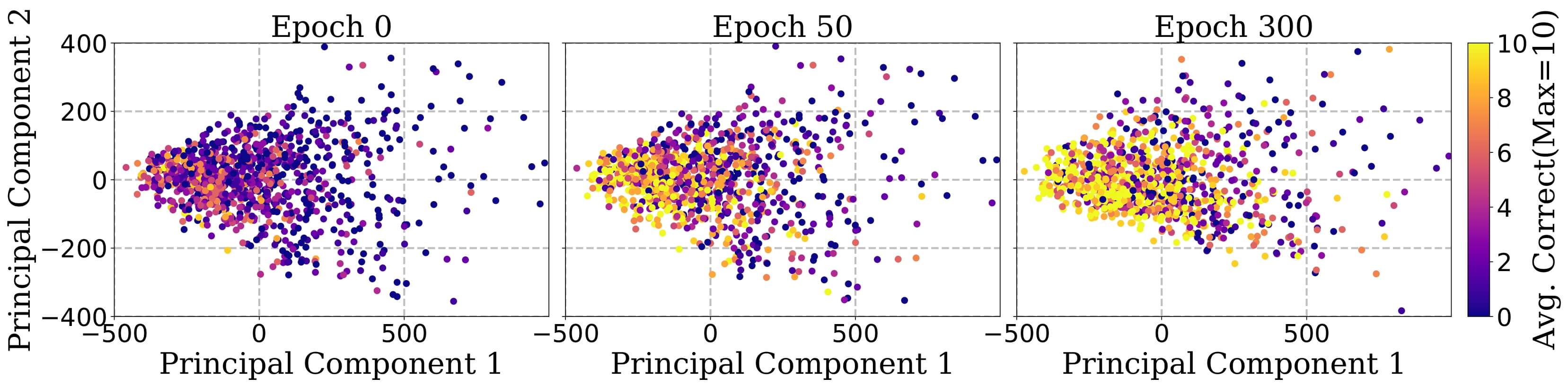
这也很好解释, 因为信号越强, 梯度越大, 模型的更新越大, 越容易在训练的早期阶段学会. 同时, 文章也可视化了神经元的激活情况, 可以发现神经激活情况也逐渐收敛, 且远离收敛簇的样本正确率更低.
Framework
总结一下上面的发现, 文章提出了一个基于角度的信号, 信号越强, 学习越快.
所以先用 pre-filling 阶段对数据集进行排序, 并根据每个 step 的训练结果调整数据的采样概率.
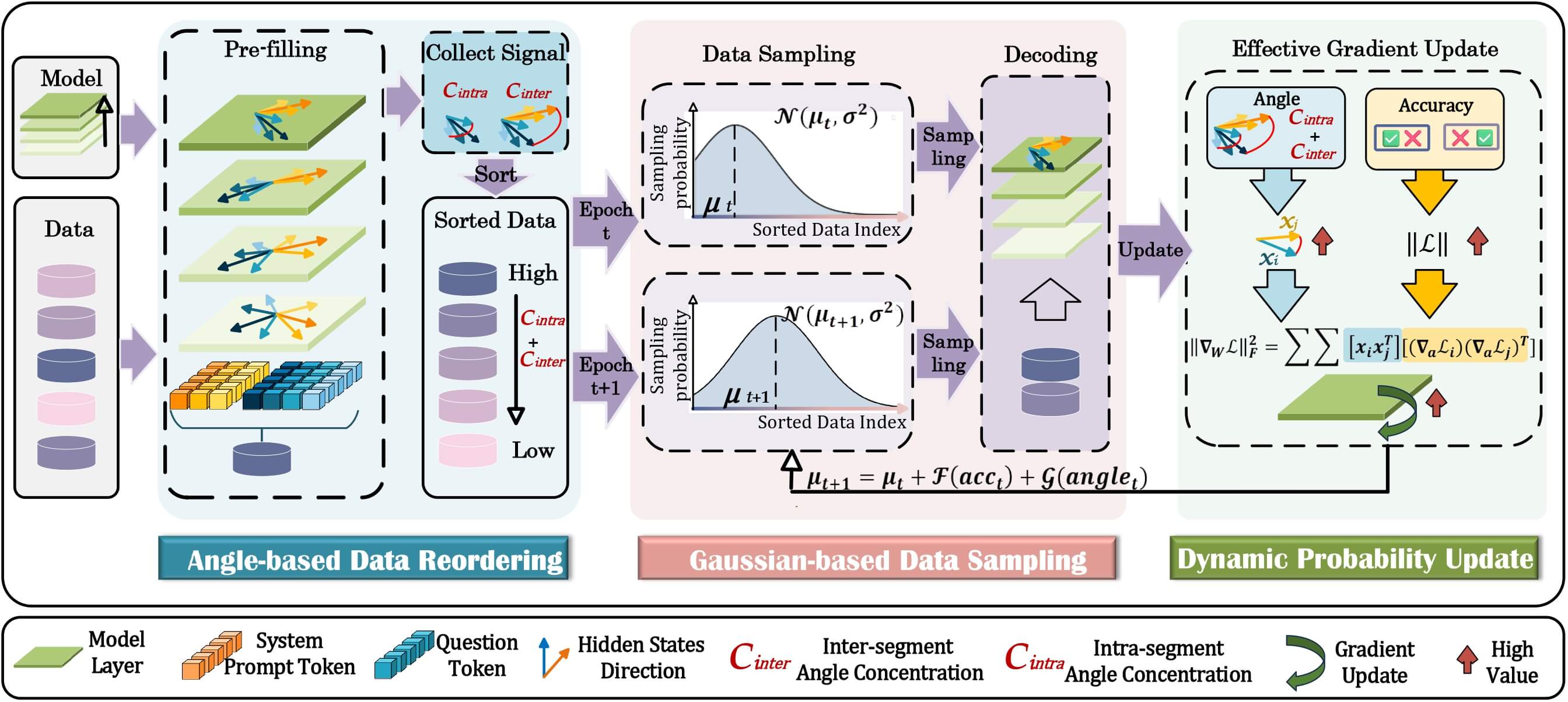
总体上我感觉这篇文章内容十分流畅清晰.