
Link: VertexRegen: Mesh Generation with Continuous Level of Detail.
一种 Coarse-to-Fine 的从点云生成 Mesh 的方法, 每一步做 edge_collapse 的逆操作, 即 vertex_split, 每一个中间结果都是合理的 Mesh.
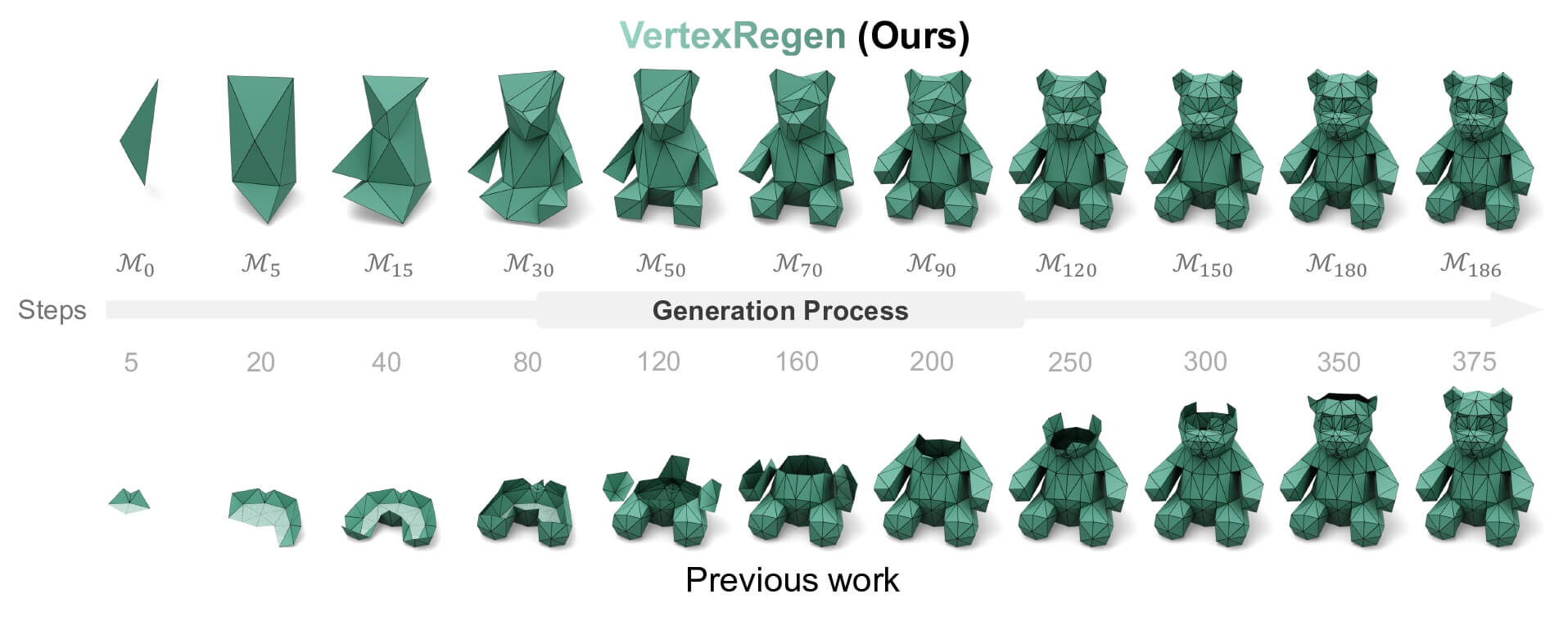
过去的工作有以下问题: 密铺 (over-tesselation), 不平滑的表面 (bumpy artifacts) 和缺失几何细节 (insufficient geometric detail).
Recently Mesh Autoregressive Generation Works:
[NVIDIA] Meshtron: High-Fidelity, Artist-Like 3D Mesh Generation at Scale
尝试增加生成的 Mesh 面数量, 提高顶点的密度. 需要更高质量的数据集和 more scalable 的模型架构. 如何 scale 现有的模型是一个十分困难的问题, 更加精细的 Mesh 需要更多的 Tokens, 在效率和鲁棒性上是很大的挑战. MeshGPT 用 VQ-VAE 来减少 Tokens 数量, MeshAnything 用 Mesh Compression Algorithm 来减少 Tokens 数量, 但是仍然不够. 在生成新的面时, 前几个点往往是重复的, 而最后的点往往是新出现的, 通过观察 perplexity 可以证实这个猜测, 基于这个观察, Meshtron 采用了 Hourglass Transformer 而不是 Full-Self Attention, 使得不同位置的 Tokens 会进入不同深度的 Transformer Block, 从而调整算力分配, 从而解决 scale 的效率问题. 第二个观察是 Mesh Ordering, Mesh 顶点的顺序是从下到上逐层排序的, 假设 global condition 设计地足够充分, 那么生成一个新的面只需要相邻的面, 也就是相邻的若干的 Tokens, 所以使用了 Sliding Window Attention, 并辅以 rolling KV-Cache 在推理时获得更大的感受野 (因为不同的深度的 Token 有超过 Window Size 的信息). 另一个在架构上的变化是把 Self Attention 换成了 Cross Attention, 用 global condition 直接作为条件, 而非 concat 在序列的开头.
[NIPS2024] MeshXL: Neural Coordinate Field for Generative 3D Foundation Models
验证了 Neural Coordinate Field 作为隐式坐标表达的有效性.
[ICLR2025] MeshAnything: Artist-Created Mesh Generation with Autoregressive Transformers
第一个提出以点云作为 Mesh Generation 的条件, 用 VQVAE 对输入编码, 整体采用 Self Attention.
每一次 edge_collapse 都会消失一个顶点和两个面, 所以逆操作只需要四个点就能表示.
从实验结果来看, 在点面数多的情况下, 效果基本持平, 但由于其独特的生成方式, 在点面数限制的情况下更能表达整体结构. 整体故事讲得不错.